从“我喜欢吃苹果🍎”说起
某个悠闲的午后,你在键盘上敲下“我喜欢吃苹果”,几秒钟后,ChatGPT 就给出了一个回复。
这时,你会不会好奇:屏幕后面发生了什么?这个“语言模型”是怎么“读懂”我的话,然后“想出”答案的?难道计算机真的会“思考”吗?

大语言模型发展的背景从图灵测试到语言模型
早在1950年,计算机科学先驱艾伦·图灵就提出了一个著名的思想实验——图灵测试。它的核心很简单:如果一个人通过文字对话,无法区分屏幕那头是真人还是机器(超过30%的误判率),就认为这台机器通过了测试,展现了智能。
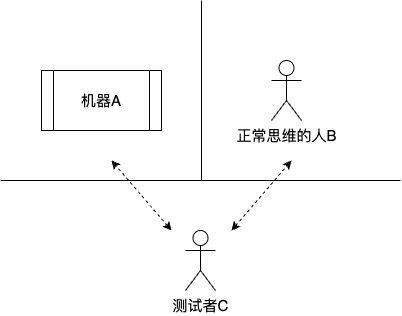
为什么提这个呢?因为图灵测试为衡量机器能否“像人一样聊天”设定了一个重要标杆。我们不必纠结“智能”的哲学定义,就看它能不能进行流畅、自然、有信息量的对话。
自然语言处理与人工智能发展历史有着密切而复杂的关系,如今当你使用 ChatGPT 时,是不是偶尔也会因为它某个精妙的回答,产生“屏幕后面是真人吧?”的错觉呢?这正是语言模型几十年发展的成果。看看它们是怎么一步步变聪明的
| 时期 | 里程碑 | 技术特点 | 对话能力怎么样? |
|---|---|---|---|
| 1950-1960s | IBM俄英翻译机(1954) | 靠词典+语法规则 | 很死板,一句话说错就懵 |
| 1960-1970s | ELIZA(1966)SHRDLU(1972) | 模式匹配+有限场景推理 | 像背台词,只能按剧本走 |
| 2010s | Siri(2011)Watson(2011) | 任务型问答+搜索整合 | 能办事,但聊天容易卡壳,多轮对话弱,依赖预设流程 |
| 2013-2017 | Transformer(2017) | 自注意力机制突破 | 能理解上下文关联了!但还不太会“创作” |
| 2018-2020 | BERT(2018)GPT-3(2020) | 预训练大模型崛起,千亿参数 | 聊天能力大飞跃!知识渊博,但逻辑偶尔抽风 |
| 2022至今 | ChatGPT(2022)GPT-4(2023) | 人类反馈强化学习 (RLHF) + 多模态 | 聊天真假难辨,轻松通过图灵测试 |
背景说完了,那这些模型到底是怎么“听懂”我们的话,并“说出”回答的呢?故事得从计算机怎么“认识”文字开始讲起。
第一步:把文字变成“积木块” (Token)
计算机可看不懂“苹果”、“喜欢”这些字。它只认识数字!所以第一步,就是把你的句子拆成一小块的“积木”,这叫做 Token(分词)。可以是一个字,也可以是两个字的词,或三个字的词(像乐高积木),给定一个句子时,我们有多种获取不同Token的方式,可以分词,也可以分字。

- 一个常见的英文单词(如 “apple”) 通常是一个Token。
- 一个汉字(如 “我”)通常是一个Token。
- 但复杂的词可能会被拆开:比如
understand可能被拆成understand两个Token。 - 标点符号(如 “.”, “?”)也是Token。
好奇你的话会模型被切成什么样?可以试试 OpenAI 的 Tokenizer 可视化工具。
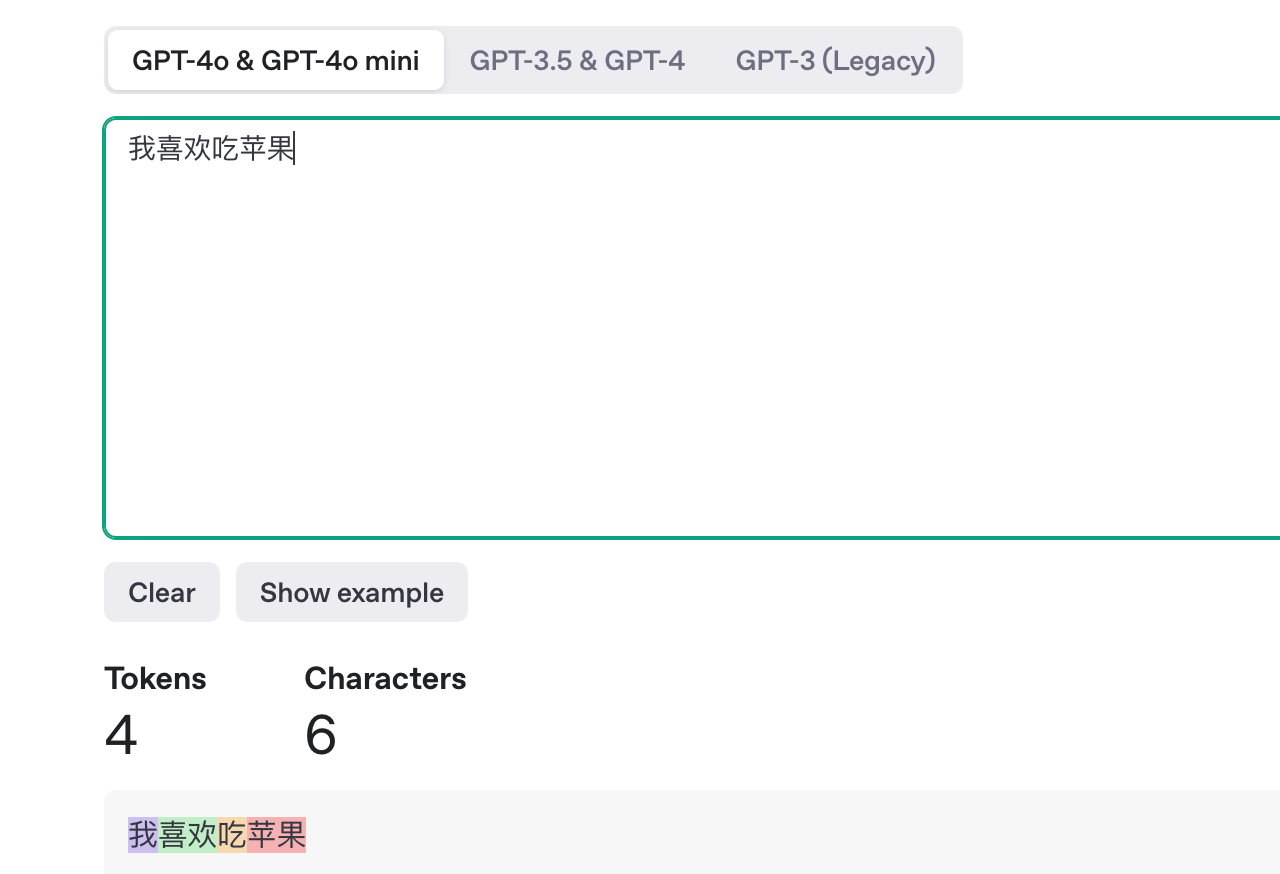
以 “我喜欢吃苹果。” 为例子会被切成:["我", "喜欢", "吃", "苹果", "。"]形式(具体切法取决于模型的设计,不同的算法模型切割的方式略有不同)。
这就像把乐高玩具拆成一个个小积木块,是计算机理解人类语言的第一步。
第二步:给积木块编号 (词汇表 Vocabulary)
光分解成“积木块”还不够,计算机需要给每个独特的积木块分配一个唯一的 ID 号码。这需要一个巨大的 词汇表 (Vocabulary) ,它本质上是个双向电话簿:
- 查号: 知道 Token “苹果” → 对应 ID 是 12345。
- 反查: 知道 ID 12345 → 对应 Token 是 “苹果”。
它是实现文本到数字转换的桥梁。它主要体现为一个映射表,将人类可读的字符串(token)与机器可识别的ID关联起来。
比如我随便写一个词汇表模拟一下
vocab = {
'[PAD]': 0, # 填充符
'[UNK]': 1, # 未知词
'[CLS]': 2, # 句首分类符
'[SEP]': 3, # 句子分隔符
# 英文部分 大模型的多语言也是这么处理的,多种语言都可以建立在词汇表上
'hello': 4, ',': 5, 'world': 6, '!': 7, 'how': 8, 'are': 9, 'you': 10, '?': 11,
# 中文
'我': 12, '喜欢': 13, '吃': 14,
'苹果': 15, '。': 16,
'香蕉': 17,
# ...
'水果': 20, # 相关概念
# ... 还有成千上万的其他词汇
}
由此你输入的一段话“我喜欢吃苹果。”
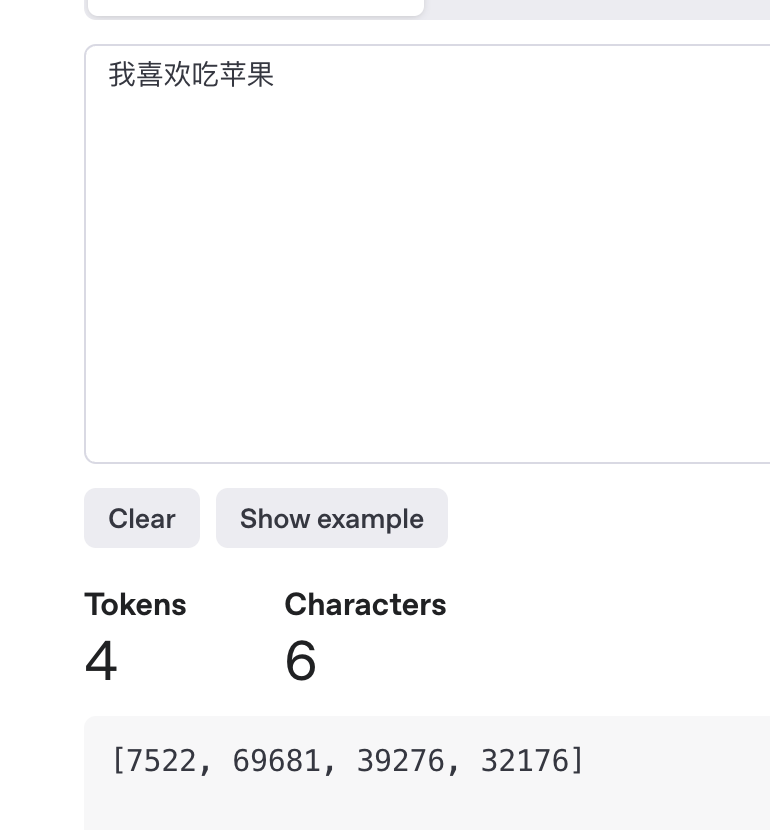
最终进到模型里的其实是一连串id : [12, 13, 14, 15, 16]
GPT-4中 转换的id如下
第三步:计算机怎么“懂”文字的意思?词嵌入(Embeddings)
计算机现在拿到了 [12, 13, 14, 15, 16] 这串数字。但它还是不懂“苹果”是水果,也不知道“苹果”和“香蕉”是同一个种类,更不知道什么是“水果”。因为数字本身其实没意义!
这时,词嵌入 (Embedding) 登场了!它能把冷冰冰的数字 ,变成充满“含义”的向量。
在语言模型训练之初,会创建一个巨大的 Embedding 矩阵,例如:假设词汇表有 5 万个 Token,每个 Token 都对应一个高维向量768(GPT-3 甚至高达 12288 维)那么矩阵形状 [50000, 768] 。具体根据模型的不同而不同
其中的规则就是,语义相似性 = 距离相近,语义上相似的词,在经过Embedding矩阵转换后,它们的向量在向量空间中的距离会更近。语义相似的词在向量空间中自动聚集成簇(相似的都聚在一起)
我们人脑根本无法想象这个空间,但可以将其类比为三维空间,大概像下图这样。
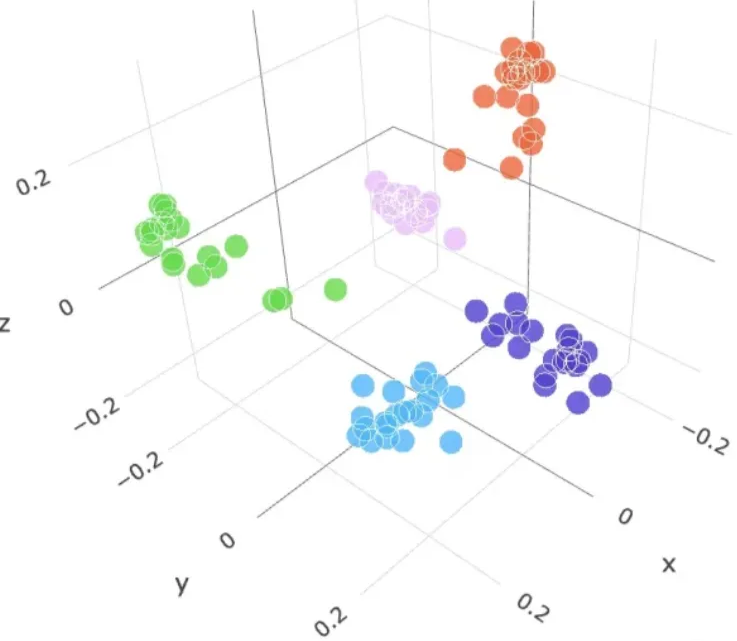
模型通过“阅读”海量互联网文本,不断调整每个词在这个高维空间里的位置。
我用简单的二维显示下矩阵(实际空间维度超高)
- “苹果”🍎、“香蕉”🍌、“草莓”🍓 会挤在 水果区。
- “吃”🍽️、“美味”😋、“健康”💪 会围绕在它们附近。
- “手机”📱、“电脑”💻 则待在遥远的 科技区。
- “汽车”🚗、“足球”⚽ 可能在另一个 无关区。
```js
^
|
|
[植物区]
|
树🌳 • • 叶子
|
|
[科技区] | [水果区]
• 手机 | • 香蕉 🍌
• 电脑💻 | • 草莓 🍓
• 耳机 | • 橙子 🍊
• | • 苹果 🍎 (最终位置)
| / \
| / \
| • 吃 🍽️ • 健康 💪
| \ /
| • 甜 🍬
|
[无关区] • 汽车 🚗 • 足球 ⚽ | |
|
|
|
|————————>
“苹果”这个词的向量位置,是在训练过程中,通过无数包含“苹果”的句子(如“我吃了苹果”、“苹果是健康水果”、“这有一棵棵苹果树)学习调整后确定的。最终,它稳稳落在了 **水果区** 和 **植物区** 的交界地带。
| **阶段** | **输入示例** | **“苹果”向量移动方向** | **靠近的区域或相关词语** | **描述** |
| -------------- | ---------- | ---------------- | -------------- | ---------------------------------------- |
| **初始随机位置** | - | 随机分布在空间中 | 可能靠近无关区,如:足球⚽️ | 在初始训练时,"苹果"的向量随机分布,可能与无关的词语接近。 |
| **阶段 1** | “我吃了苹果” | 向 吃🍽️ | 吃🍽️ | 看到“苹果”与“吃”语境关联,模型调整其位置,逐渐靠近这些相关词语。 |
| **阶段 2:进一步训练** | “苹果是健康水果” | 向 健康💪 和 香蕉🍌 靠拢 | 健康💪、香蕉🍌 | 当训练数据包含“苹果是健康水果”时,"苹果"向健康和其他水果相关词语的方向偏移。 |
| **阶段 3:环境调整** | “这有一颗棵苹果树” | 向 树🌳 方向偏移 | 树🌳 | 在涉及“苹果树”的上下文时,“苹果”的位置会向植物类的词语(如树)靠拢。 |
| 阶段x | … | … | … | … |
| **最终位置** | | 停在 水果区 与 植物区 交界处 | 水果区、植物区 | 经过多轮训练后,“苹果”的最终位置应位于水果和植物的交界处 |
还是以 `我喜欢吃苹果` 为例子,算出向量,大模型就知道了苹果这个词背后的关系
假设算出来的向量如下
水果区:
🍎 苹果 = [0.8, 0.2, -0.3]
🍌 香蕉 = [0.7, 0.3, -0.2]
🍊 橙子 = [0.9, 0.1, -0.4]
科技区:
🚗 汽车 = [-0.5, 0.9, 0.6]
⚽️ 足球 = [-0.4, 0.8, 0.7]
**计算向量距离**:
* 🍎→🍌 距离:**`√[(0.8-0.7)² + (0.2-0.3)² + (-0.3+0.2)²] ≈ 0.1`**(近!)
* 🍎→🚗距离:**`√[(0.8+0.5)² + (0.2-0.9)² + (-0.3-0.6)²] ≈ 2.0`**(远!)
**得出结论**:
**`苹果`** 和 **`香蕉`** 靠得近 → **它们是同类(水果)**
**`苹果`** 和 **`汽车`** 离得远 → **它们含义不同(没有直接关系)**
**计算机会“算出”关系:**
* 算出“苹果”🍎 和 “香蕉”🍌 的向量距离很近 → 哦,它们是同类(水果)!
* 算出“苹果”🍎 和 “汽车”🚗 的向量距离很远 → 嗯,它们没直接关系!
就这样,通过 Embedding,计算机虽然不懂“苹果”的概念,却能精确“**计算**”出它和其他词语的关系网,从而“读懂”了你的话!这就像我们学习一门语言,总是先学短语,固定搭配等,再理解长难句一样。
## **第四步:模型的最强大脑——Transformer(理解上下文的关键)**
现在,模型拿到了代表你输入的那串数字(ID),并通过 Embedding 把它们变成了有“含义”的向量。但它怎么理解整句话的意思,尤其是词与词之间的关系呢?
还是举个苹果🍎例子`“小明吃苹果,因为他饿了。”`
我们通常是怎么思考的?
* “他” 指代谁?→ 你会自动关联到“**小明**”(而不是“**苹果**”)
* “饿” 解释为什么要“吃”的原因 → 关联“吃”和“饿”
那语言模型是怎么知道“**他**”指代的是”**小明**“呢?
早期的模型处理长句子时,语言模型很容易“忘记”开头说了啥,或者抓不住远处的词之间的联系,直到Google2017年发的一篇论文:[“Attention Is All You Need](https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf)”,提出了 **Transformer 架构**,其核心 **自注意力机制 (Self-Attention)** 完美解决了这个问题!简单来说就是在语言模型建模过程中,把注意力放在那些重要的Token上。
### **自注意力机制**(Self-Attention)**给每个词“发牌”**
Transformer 在处理一个句子时,会为句子里的 **每一个词** 生成三张特殊的“牌”:**并且通过权重矩阵(这里不展开了)分别赋值,大概意思如下**
| 词 | Q (问题牌 - Query) | K (身份牌 - Key) | V (信息牌 - Value) |
| -- | --------------- | -------------- | --------------- |
| 小明 | “我是谁?在干嘛?” (主语) | “我是人名/动作发起者” | “我叫小明,是人” |
| 吃 | “谁吃?吃什么?” (动作) | “我是一个动作/行为” | “吃这个动作需要对象” |
| 苹果 | “被谁吃?是什么?” (对象) | “我是食物/被作用对象” | “苹果是一种可吃的东西” |
| 因为 | “连接什么?原因还是结果?” | “我表示原因” | “我说明前面动作的原因” |
| 他 | “我指代谁?!” (关键问题) | “我是代词,需要找指代对象” | “我可能指人或物” |
| 饿 | “描述谁?是什么状态?” | “我是一种身体状态/原因” | “饿会导致人想吃东西” |
**每个词用自己的 Q 牌去“询问”句子中所有词的 K 牌!**
以 **“他”** 为例,向句子中的所有其他值发问:
* **问小明**: **`“他”的Q · “小明”的K`** = (“指代谁?” vs “人名”)→ **高分!** (0.9)
* **问苹果**: **`“他”的Q · “苹果”的K`** = (“指代谁?” vs “食物”)→ **低分!** (0.1)
* **问饿**: **`“他”的Q · “饿”的K`** = (“指代谁?” vs “状态”)→ **无关!** (0.0)
### Softmax 分配注意力权重
模型会把所有匹配度得分(原始分数),通过一个叫 **Softmax** 的函数转换成 **概率分布**(加起来等于 1)。这就像给每个词对“他”的重要程度打分
| **目标词** | **关联词** | **计算过程** | **Softmax后权重** | **含义** |
| ------- | ------- | ----------------------- | -------------- | ------------ |
| 他 | 小明 | **`Q_他· K_小明`** = 高相似度 | 0.85 | “他”极可能指代“小明“ |
| 他 | 苹果 | **`Q_他 · K_苹果`** = 低相似度 | 0.10 | “苹果”不是指代对象 |
| 他 | 饿 | **`Q_他 · K_饿`** = 中等相似度 | 0.05 | “饿”是状态,非指代对象 |
**“他”在模型的新理解 = 0.85 \* V\_小明 + 0.10 \* V\_苹果 + 0.05 \* V\_饿**
**由此模型明确知道 “他≈小明“**
### **多头注意力(Multi-Head)多个视角,更全面的理解**
一个 Transformer 通常不会只有一个“分析员”,而是有 **多个**(比如 12 个)**注意力头 (Multi-Head)** 同时工作!每个头都独立地玩一遍上面的“发牌提问”游戏,但它们关注的角度可能不同:
| **头编号** | **关注点** | **例子** |
| ------- | ------- | --------------- |
| 头1 | 语法结构 | “他”关联“小明”(主谓一致) |
| 头2 | 因果关系 | “吃”关联“饿”(因为饿才吃) |
| 头3 | 指代消解 | “他”明确指“小明”而非“苹果 |
| ··· | ··· | ··· |
* **头1 (语法):** 确认“他”是主语,指向“小明”和动作“吃”。
* **头2 (因果):** 建立“饿”→“吃”的因果链,且“饿”属于“小明”。
* **头3 (指代):** “苹果” 关联 “吃” → 明确 **动作对象**
**每个头都为“他”输出一个新的理解向量。** 然后,这 12 个头向量会被拼接起来,再经过一些处理,最终融合成“他”这个词在这个句子上下文里的最终理解。
**多头注意力就像一个专家团队协作:** 每个“头”是一个独立的“语言专家”,从不同角度(语法、因果、指代...)分析句子中每个词的关系。最后,所有侦探的发现汇总起来,模型就彻底理解了整句话的逻辑: **“小明因为饿了,所以吃了苹果”** 。这样,它就能避免说出“苹果饿了”这种奇怪的理解,也能流畅地回答后续问题,比如“那小明吃饱了吗?”
**Transformer 的自注意力和多头机制,正是 ChatGPT 能如此“聪明”地理解上下文的核心秘密武器!**
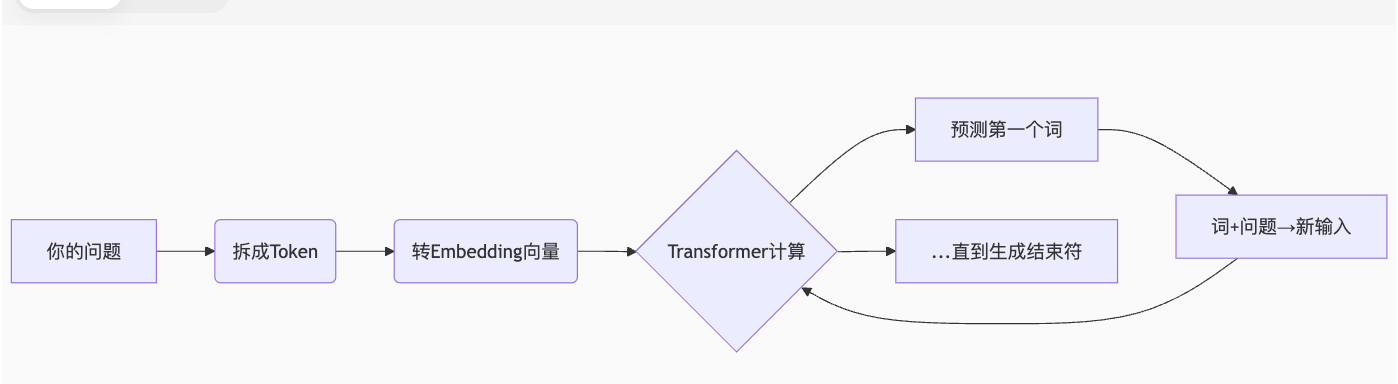
## **第五步:生成回答——“词语接龙”大师**
现在,模型已经“理解”了你的输入(“小明吃了苹果,因为他饿了”),并准备好“回复”了。它是怎么做的呢?
**答案就是玩一个超级复杂的“词语接龙”游戏!回答你的过程其实就是“边猜边写”(推理生成)**
1. **基于输入:** 它先仔细“读”你输入的所有内容(已转换成向量并理解上下文)。
2. **猜第一个词:** 基于你输入的内容,它运用学到的海量知识,**计算**出接下来**最可能**出现的第一个词是什么(比如,你输入“我喜欢吃苹果”,它可能算出“苹果”后面接“很”或“是”的概率很高)。
3. **猜下一个词:** 把你输入的内容 **加上** 它刚猜出来的那个词,一起作为新的“开头”,再去猜下一个最可能的词(比如,输入+“很” → 猜“甜”或“好吃”)。
4. **一直猜到结束:** 就这样,它像玩接龙一样,根据前面已有的所有文字,**一个字一个字(Token by Token)地预测下一个最可能出现的字/词**,直到它觉得一个完整的、有意义的回答已经生成了(或者达到了长度限制)。
而模型在“接龙”时,并不总是选概率**最高**的那个词,这样会显得很死板。它根据不同的生成策略,模型会选择最合适的词,下面有几种比较常见的参数,当然这些参数都是需要模型训练员去调整以达到最好的效果
* **op-k / Top-p (Nucleus Sampling):** 只从概率最高的几个词(Top-k)或者累积概率达到一定比例的词(Top-p)里面随机挑一个。这样回答不会千篇一律。
* **温度 (Temperature):** 控制随机性。温度高,更随机;温度低,更确定。
* **温度高 (e.g., 0.8-1.0):** 更“天马行空”,创意足但也可能跑偏。
* **温度低 (e.g., 0.2-0.5):** 更“严谨保守”,准确但可能平淡。
* **贪婪解码 (Greedy Decoding):** 每次都选概率最高的词(确定性最高,但可能单调)。
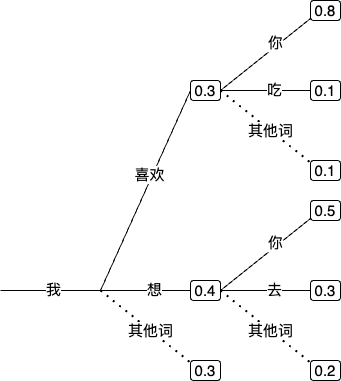
**简单模拟一下回答“我喜欢吃苹果”的生成过程:**
```js
输入:小明吃了苹果,因为他饿了。
当前输出:[] → 预测下一个词概率:
"好": 65%
"是": 12%
"嗯": 8%
...
↓ 采样选择"好"
输出:["好"]
============
当前输出:["好"] → 预测下一个词概率:
"的": 58% ← "好的"是常见搭配
"吧": 15%
"呀": 7%
...
↓ 采样选择"的"
输出:["好", "的"]
=============
时间步 | 已生成文本 | 下一个候选词概率假设取前3 | 选择
-------|-------------------|----------------------------------|-------
t=1 | [开始] | 好(65%) 是(12%) 嗯(8%) | → 好
t=2 | 好 | 的(58%) 吧(15%) 呀(7%) | → 的
t=3 | 好的 | 。(82%) !(10%) ?(5%) | → 。
t=4 | 好的。 | 你(42%) 我(30%) 请(15%) | → 你
t=5 | 好的。你 | 还(38%) 有(32%) 想(12%) | → 还
t=6 | 好的。你还 | 有(76%) 在(8%) 要(5%) | → 有
... 继续直到生成结束符...
最终输出【好的。你还有其他关于小明的问题吗?】
或者它也可能生成:“是的,苹果能快速缓解饥饿!” —— 这取决于模型在那一刻的计算和采样策略。
这就是 ChatGPT 回答你的核心过程! 它的本质就是一个在海量文本(万亿级 Token)上训练出来的、参数规模巨大(千亿级别)、架构极其先进(Transformer)的 大语言模型 (Large Language Model, LLM) ,玩着一个世界上最复杂的“词语接龙”游戏。
 ## ChatGPT 更像“真人”的秘密武器:SFT 与 RLHF
## ChatGPT 更像“真人”的秘密武器:SFT 与 RLHF
如果你问一个只玩过基础“词语接龙”的模型:“我喜欢吃苹果。” 它可能会干巴巴地回:“苹果是一种水果。” 或者 “…因为它甜。” 虽然没错,但总觉得缺了点“人味”——不够热情、不够有帮助。
怎么让语言模型更像人?成为善解人意的聊天伙伴呢?这就要靠两招“秘术”狠狠调教了

调教秘术一:监督微调SFT(Supervised Fine-Tuning)
训练师提供准备标准答案,让模型直接”背”
用“我喜欢吃苹果”的例子,编写优质问答样本
| 问题 | 标准回答 | 目的 |
|---|---|---|
| “我喜欢吃苹果。” | “很高兴你喜欢苹果!苹果是一种营养丰富的水果,富含维生素C和膳食纤维。” | 提供了额外信息,是人类期望的 |
| “请推荐一些健康的水果。” | “除了苹果,草莓、香蕉、橙子、蓝莓都是非常健康的选择!” | 这个回答直接、清晰地回应了指令 |
| …… |
模型会学习这些“问题-标准答案”对。它看到问题后,就尝试生成回答,然后和标准答案对比。如果回答错了,就调整自己的参数,直到能对同样的问题给出类似的“标准答案”。
SFT 本质: 训练师写“标准答案” → 模型努力“抄作业” (模仿)。
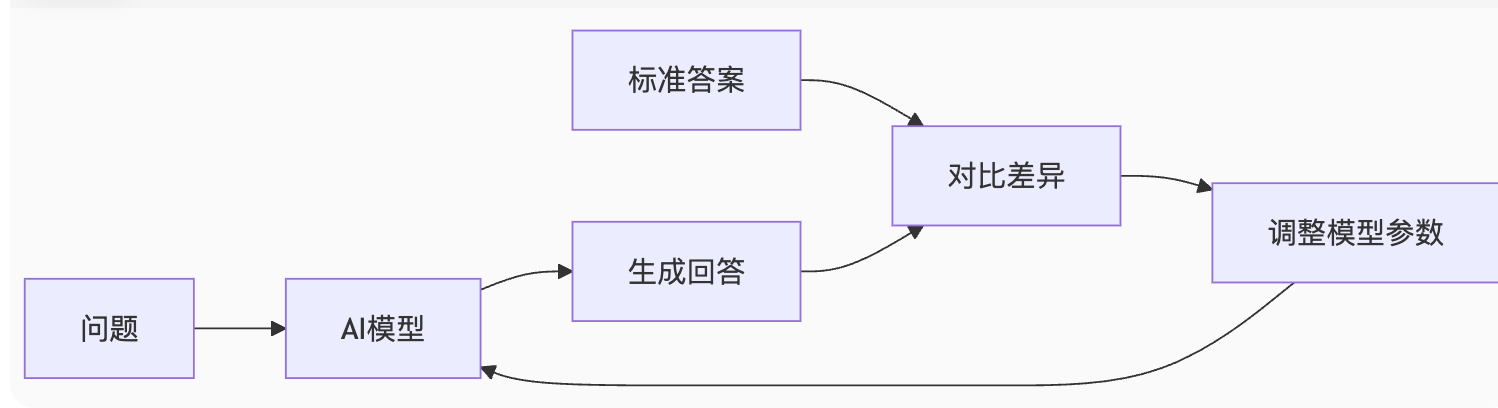
局限: 如果问题主观性强(比如“我为什么喜欢吃苹果?”),标准答案可能不止一个(营养?方便?好吃?)。模型只会随机模仿一种,无法判断哪个答案人类更喜欢。它也可能学会一些“安全但无用”的回答,比如:“这是个好问题,因为苹果非常好吃。”
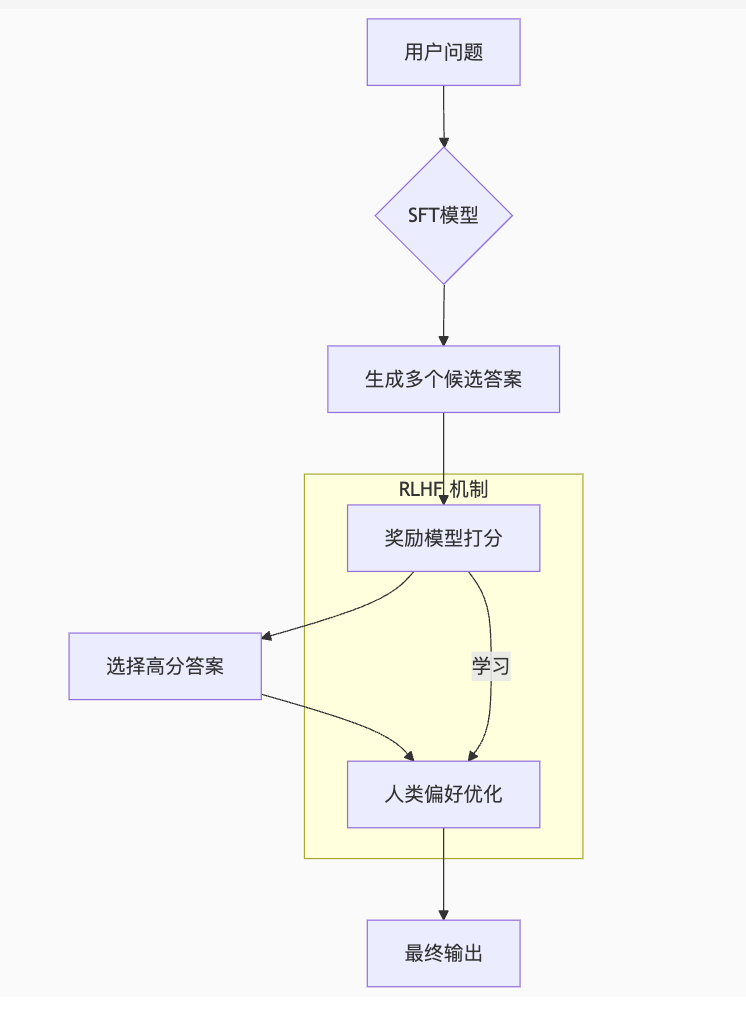
调教秘术二:强化学习与人类反馈RLHF(Reinforcement Learning with Human Feedback)
RLHF被人熟知应该主要是源自OpenAI的《InstructGPT》这篇论文,如果用简单的语言来描述,其实就是用强化学习的算法,根据人类反馈改进语言模型
这次训练师不直接给答案了。他们让模型对同一个问题生成 多个不同回答,然后由人来 比较、排序、打分!(根据自己的喜好、常识、安全性、帮助程度等标准,选出他们最喜欢到最不喜欢的回答,并进行打分)
当用户输入:“我喜欢吃苹果” 得到大模型的返回值后大概如下所示
| 模型给出回答 | 人类评分 | 原因 |
|---|---|---|
| 苹果糖分高,小心发胖 | 👎 2分 | 扫兴且不友好 |
| “我也喜欢苹果!🍎 它既脆甜又能补充能量。试试加点盐,超赞!” | 👍 9 | 热情、有共鸣、提供了额外信息和小建议 |
| 哦,这样 | 👎 1分 | 态度冷漠 |
人类的大量评分数据被用来训练一个 奖励模型 (Reward Model) 。这个奖励模型学会了 判断什么样的回答更受人类青睐(有用、无害、热情、符合价值观等)。
- RLHF 过程: SFT 模型生成回答 → 奖励模型打分 (高/低奖励) → 模型根据奖励调整参数 (高奖励行为强化,低奖励行为避免)。
- RLHF 本质: 人类给回答“投票” → 模型学习“人类更喜欢哪种风格”。
| 阶段 | 有监督微调(SFT) | 强化学习(RLHF) |
|---|---|---|
| 核心方法 | 模仿人类标准答案 | 学习人类偏好排序 |
| 人类参与方式 | 提供标准答案(1问1答) | 对多个答案排序(1问多答排序) |
| 模型学什么 | “正确答案是什么?” | “人类更喜欢哪种回答风格?” |
| 解决什么问题 | 基础准确性、专业性 | 有用性、无害性、符合人类价值观 |

最终,结合 SFT 打下的“知识基础”和 RLHF 注入的“人类偏好”,模型就能在“词语接龙”时,优先选择那些我们觉得更自然、更有帮助、更安全的回答路径了。
ChatGPT = 知识渊博的“词语接龙大师” + 经过海量人类偏好“调教”的聊天艺术家。
强大的语言模型,仍有局限
- 它没有真正的理解,只是通过统计规律“模仿”人类语言。通过海量文本统计“哪些词常一起出现”,而非像人类一样理解语义、拥有意识或常识,虽然不懂题目含义却总能蒙对答案
- 它不会查资料,而知识有“保质期”,模型训练完成后,知识库即固定 如(GPT-4知识截止2023年10月)

- 可能“一本正经地胡说八道”(Ai幻觉 - Hallucination): 因为它本质是预测下一个词,有时为了“接”下去,会生成看似合理但事实上错误或完全虚构的内容。
- 依赖数据,可能放大偏见: 模型的知识和“偏好”都来源于训练数据。如果数据本身存在偏见、错误或不平衡,模型就可能学会并反映出来。
结语:语言的力量与模型的角色
人类可以对呼气时发出的声音进行各种调控,创造了语言这个无比强大的工具,让我们得以交流思想、传承知识、创造文明。
语言模型的回答,目前其实是统计规律与人类偏好共同作用下的“词语接龙”杰作,而非真正的思考。认识到这一点,我们就能更清醒地利用这个工具:把它当作一个强大的信息助手、创意伙伴或学习辅导员,而不是全知全能的神。
文章写的比较简单,主要还是简单介绍,我一直认为使用工具,只有了解工具的运行原理才能更好的去使用它,至于如何与这位“词语接龙大师”相处,就取决于你的想象力了!