本文章是在帮助您从零开始使用SillyTavern(酒馆)与DeepSeek等AI模型进行交互,完成基础环境与搭建,帮助各位在网页端体验跑团的魅力,最近自己再折腾酒馆发现掘金板块中好像没有这类相关教程,我直接分享一下我自己的体验.
本文中的角色卡和预设等信息出自社区类脑 Discord , 后文的大部分资源都出自这里.如有侵权可删
话不多说先看效果
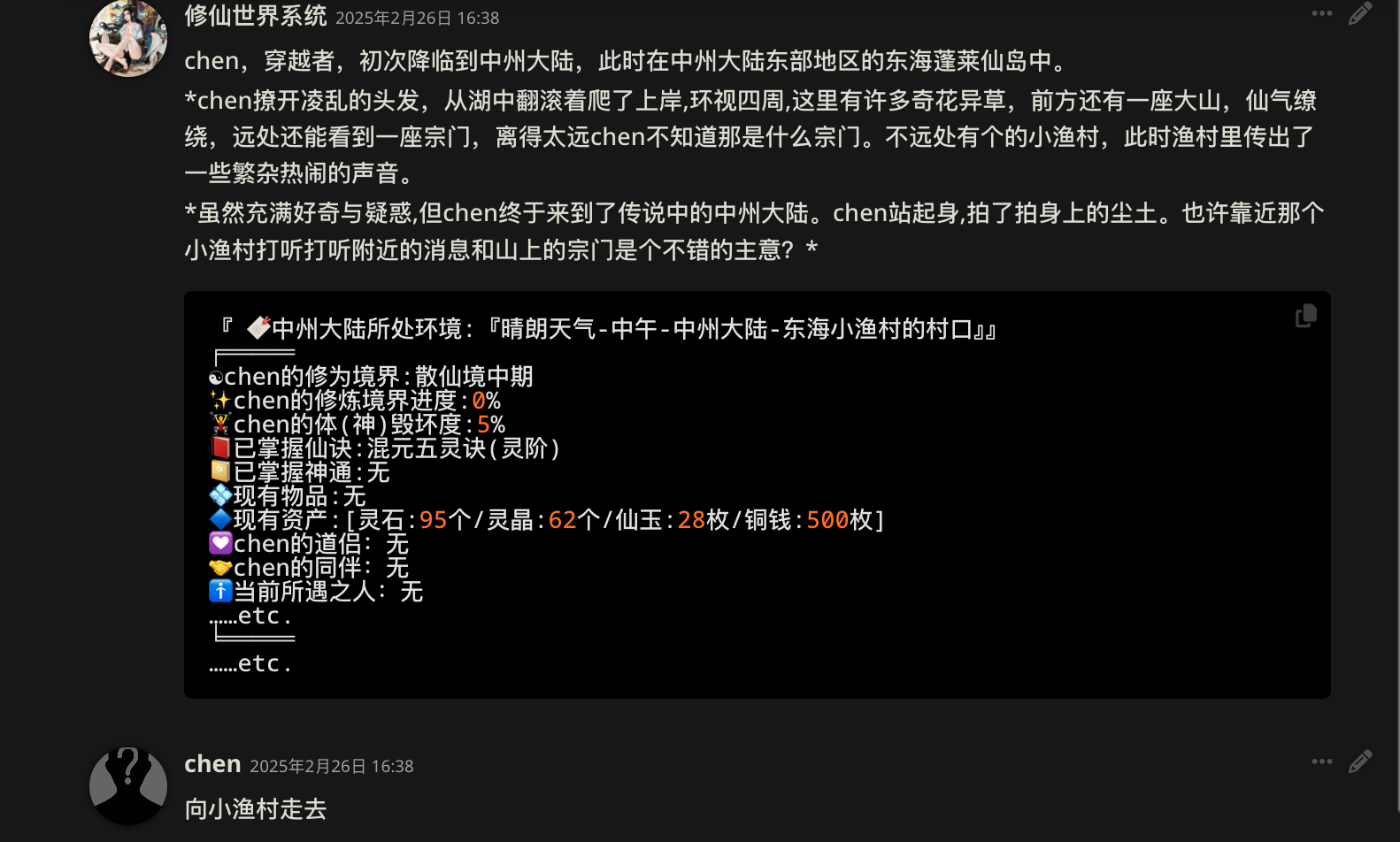

随手玩的聊天记录,可以看到不论是自由度,还是表现力,都十分不错,在AI的加持下,线上个人跑团打发时间我觉得已经十分可行,接下来我们以实现这一目标为基础开始搭建我们自己的酒馆。
SillyTavern 是什么?
首先我们要先了解什么是SillyTavern(简称ST或者酒馆),在官方的定义中它是作为前端页面通过接口与各种LLM连接,主要是让用户与文本生成LLM、图像生成引擎和TTS语音模型进行交互。它提供了丰富的功能来定制AI对话体验,特别适合角色扮演、创意写作和各类互动场景。
SillyTavern 和直接通过网页端设置prompt跑团有什么区别?
| 对比维度 | SillyTavern | 直接 Prompt 跑团 |
|---|---|---|
| 功能定位 | 专为 RP 设计的集成化工具(预置角色卡/插件/记忆管理) | 需要手动设计完整 Prompt 结构(需自行规划世界观/规则约束) |
| 记忆管理 | 分层自动管理(短期缓存 → 关键事件提取 → 长期存储) | 需手动维护记忆链条(需定期用 [记忆摘要] 更新上下文) |
| 输出控制 | 通过预设模板规范输出格式(自动分段/选项生成) | 需详细编写 [输出要求] 约束(如字数限制/选项数量/语言风格) |
| 沉浸体验 | 支持多模态集成(自动生成角色立绘/环境音效) | 需自行整合其他工具(需手动调用绘图/语音合成 API) |
| 维护成本 | 自动更新机制(通过 Docker 可一键升级) | 需人工跟踪迭代(需定期调整 Prompt 适配模型更新) |
| 适用场景 | 长期持续性跑团(自动维护剧情连贯性) | 短篇实验性创作(快速测试特定设定) |
最重要的随着你的聊天记录越来越多,就会有越来越多的内容被推出上下文(AI会忘记)。但是SillyTavern 可以让一些重要内容不被推出去,保证了跑团体验的流畅性。
这是我随手画的流程图,整个交互逻辑大概就是这么个流程
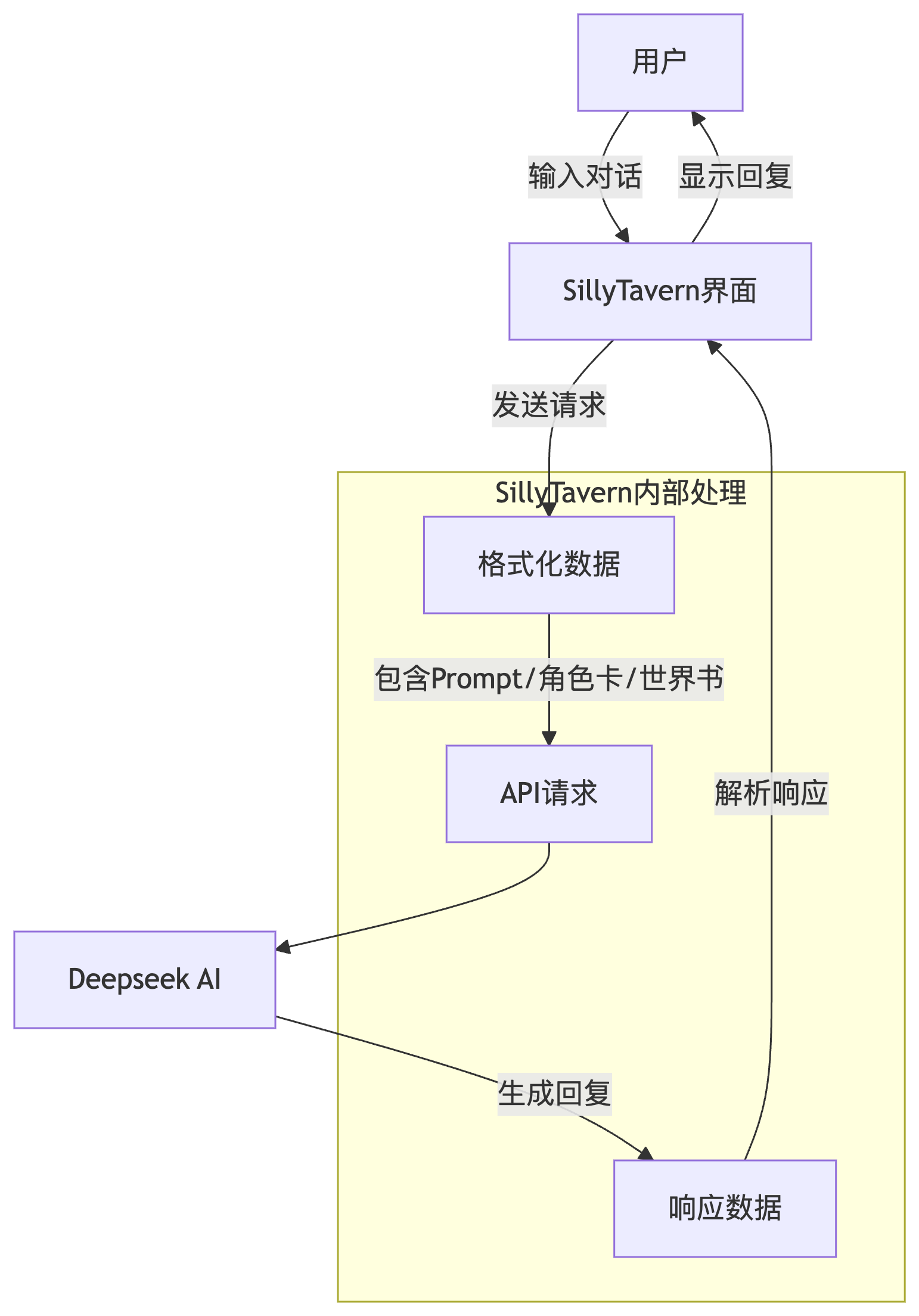
安装SillyTavern,构建环境
接下来我们进行环境配置,以我Mac环境为例,更多详细的设置可以参考官方文档
- 安装NodeJS(建议使用最新 LTS 版本)至少要NodeJS 18 以上
- 找个目录使用 Git 克隆 SillyTavern
git clone <https://github.com/SillyTavern/SillyTavern> -b release
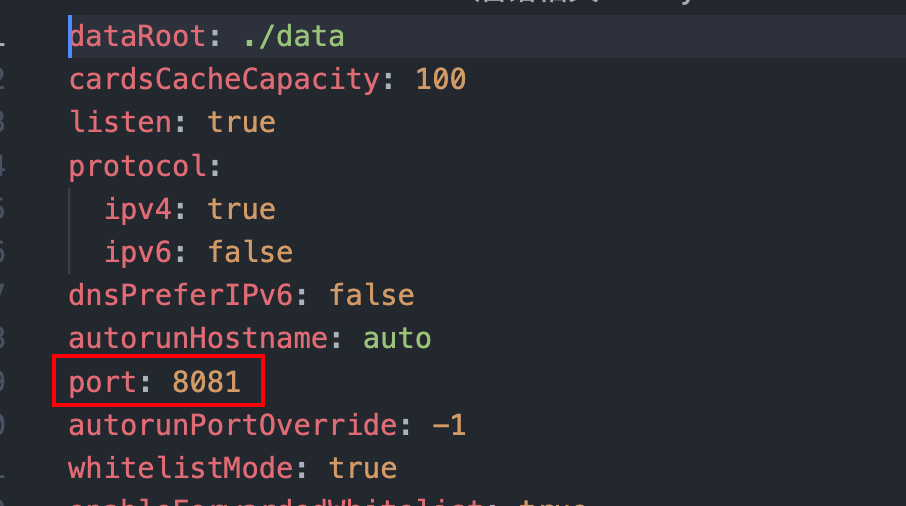
cd SillyTavern导航到安装文件夹。运行bash start.sh会自动帮你安装依赖,默认的端口是8080如果遇到端口被占用可以到此处config.yaml配置文件进行修改
- 正常成功启动的话访问应该是这个界面
配置SillyTavern
1. 设置(导入)预设,
启动SillyTavern后,点击界面上的第一个按钮,然后导入预设文件。这可以帮助你快速设置合适的配置。
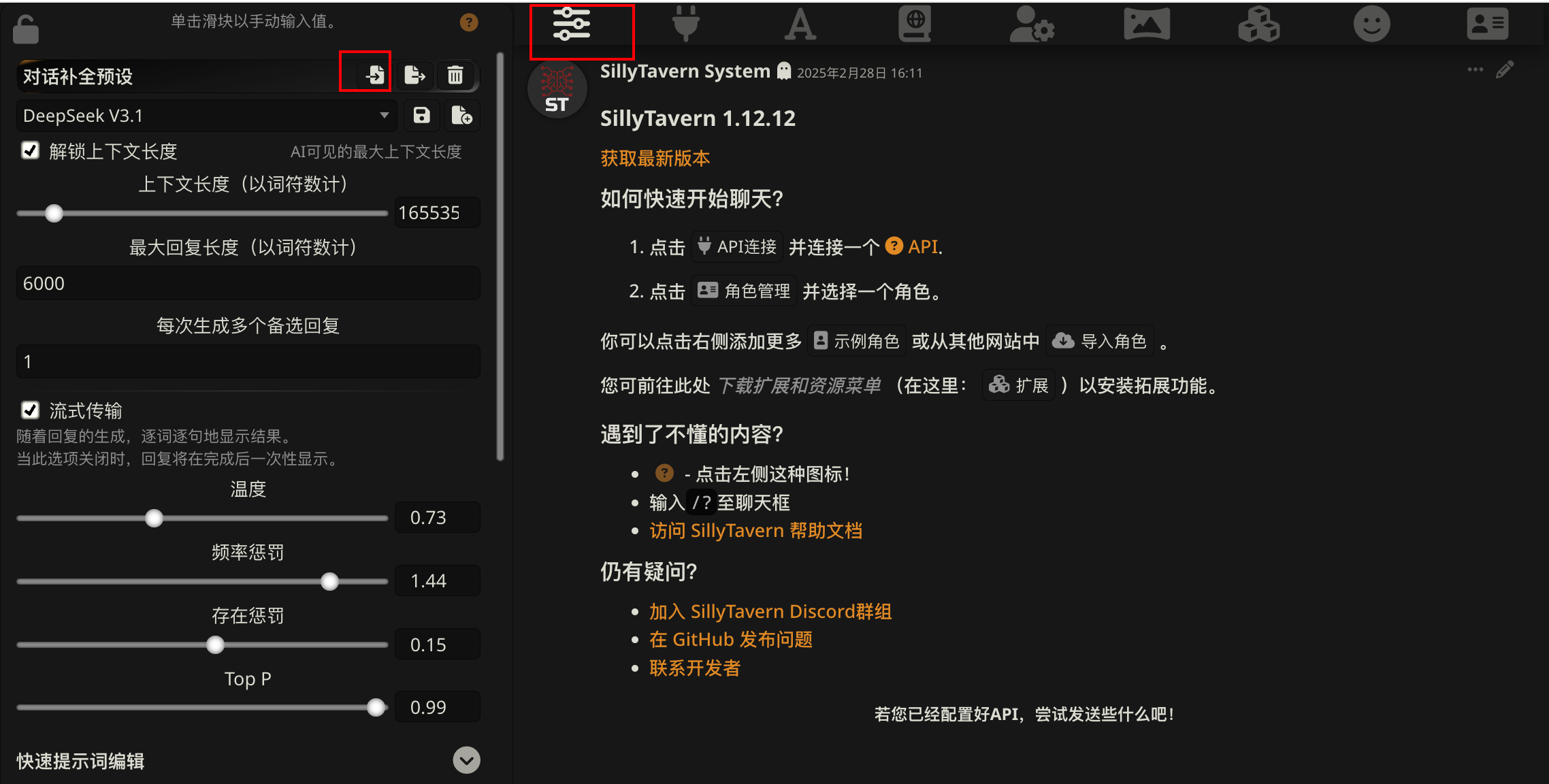
这些参数具体的作用我列在这里
| 参数 | 常见默认值 | 理念 |
|---|---|---|
| 温度(temperature) | 0.7-1.0 | 控制生成文本的随机性和创造性。较高的值(如1.0以上)产生更多样化但有时不太连贯的输出,较低的值(如0.2-0.5)产生更确定、一致但可能缺乏创造性的回复。0.7-1.0是平衡确定性与创造性的理想范围。 |
| 上下文长度 | 根据模型而异(通常4K-32K) | 决定模型能”记住”的对话历史长度。更长的上下文使模型能参考更多历史消息,提供更连贯和相关的回复,但会增加处理时间和资源消耗。 |
| max_tokens | 根据模型而异(通常几千) | 限制生成回复的最大长度,简短回答可设较小值,复杂分析则需更大值。提供足够空间表达完整思想是关键。 |
| 流式传输(stream) | false | 控制回复的传输方式。设为true时,回复会实时流式传输(像打字一样逐步显示)设为false时,仅在完整生成后一次性返回全部内容,适合需要一次处理完整回复的场景。 |
| 频率惩罚(presence_penalty ) | 0 | 值越高,模型就越倾向于使用更多样化的词汇,避免重复。通常取值范围在0到2之间,值为0表示不进行频率惩罚 |
| 存在惩罚(frequency_penalty) | 0 | 值越高,模型就越倾向于引入新的话题而不是继续已有的话题。通常取值范围也在0到2之间。 |
| top_p | 1.0 | 考虑所有可能性,如果Top_p=0.9意味着模型只会从累积概率达到90%的词汇中选择。这有助于平衡文本的创造性和连贯性。 |
| top_k | undefined/不启用 | 不限制词汇选择范围 |
如果你用deepseek-r1的话,官方推荐第三方的温度设置0.6,r1文风还挺颠的,可能在修仙的大背景下突然冒出外星飞船😂,用其他例如claude-3.5的话就好很多了
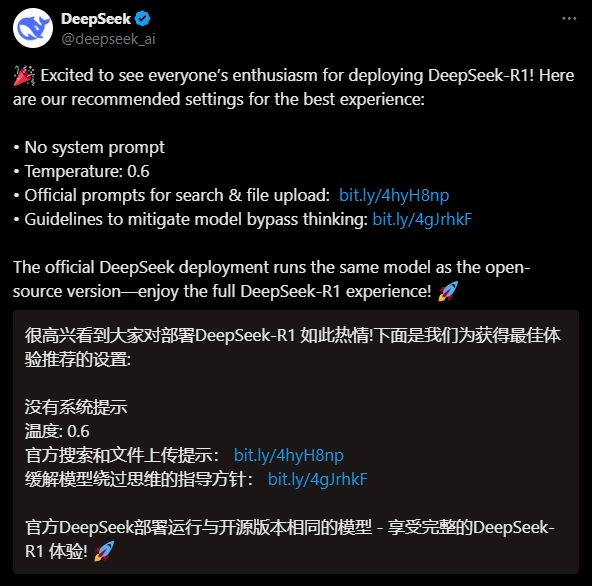
下面我简单举2个例子,你可以以此为基础设置你想要的预设
-
客服机器人:
- 低temperature (0.3-0.5)
- 较高presence_penalty (0.3-0.6)
- 适中max_tokens
- 目的: 一致、准确但不重复的回答
-
创意写作机器人:
- 高temperature (0.8-1.2)
- 适中frequency_penalty (0.2-0.4)
- 高max_tokens
- 目的: 富有创意和多样性的内容
但是如果你懒我这里也分享一下我自用的预设,下载后是一个json文件直接导入即可.
2. API获取与连接
关于API密钥的获取,如果你是本地有部署语言模型的话可以url直接填本地模型的端口即可,如果你使用的是模型服务,例如deepseek,claude等,就要去他们的控制台创建一个apikey,现在很多平台注册就会送key,我这里就不给自己引流了,如果实在不知道那里可以留言联系我。
API链接我这里以第三方DeepSeek-v3为例,具体步骤如下:
- 点击”连接”按钮(屏幕右上角第2个)
- 选择”自定义(兼容openAi)”
- 输入
API密钥需要自己去模型服务商获取 - 点击链接,链接成功后会返回可选的模型列表,你自己选一个你要是使用的模型
- 选择模型我这里使用的是
DeepSeek-v3 - 提示词后处理可以选择严格
- 点击”发送测试消息”按钮,可以检测是否链接成功
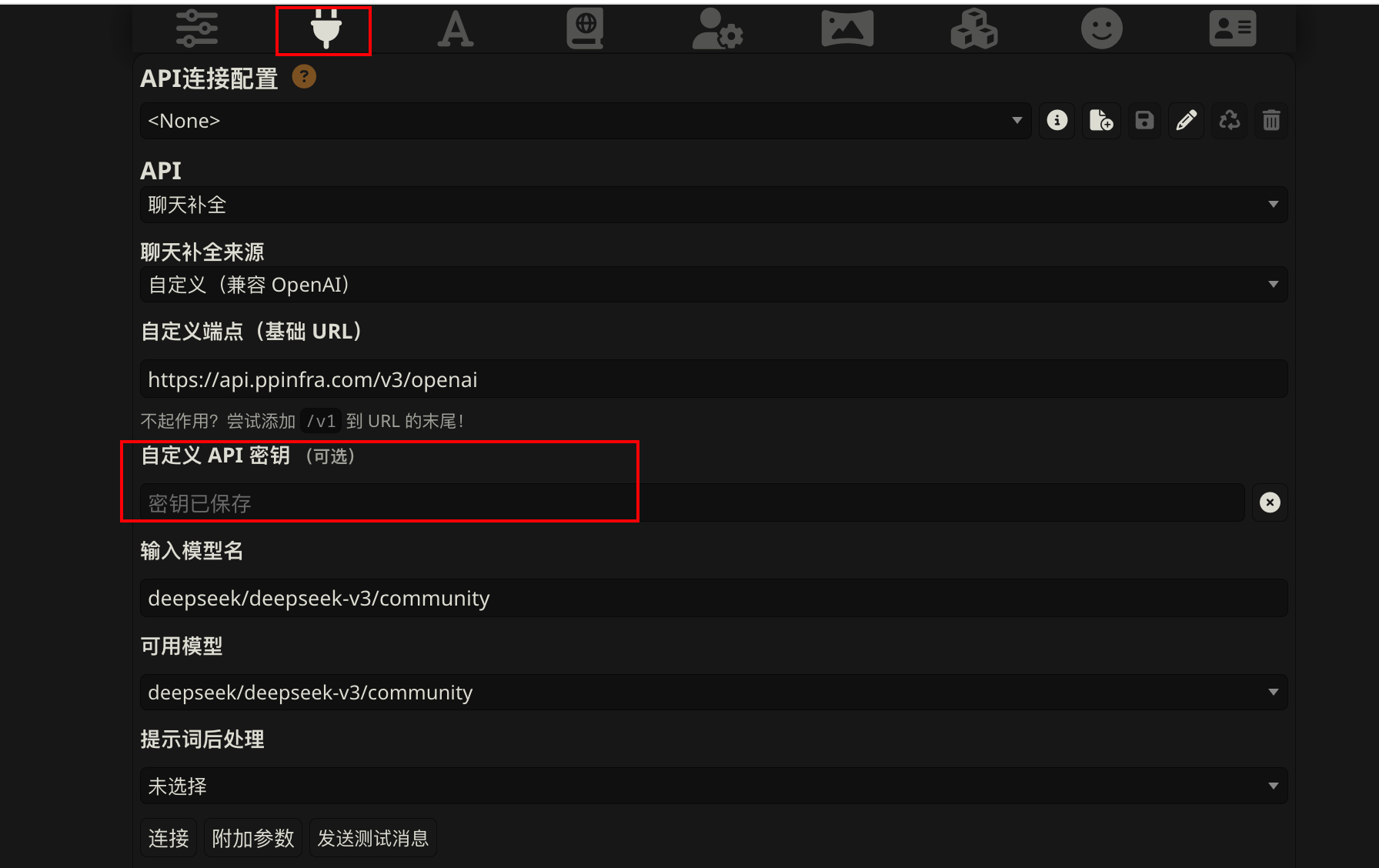
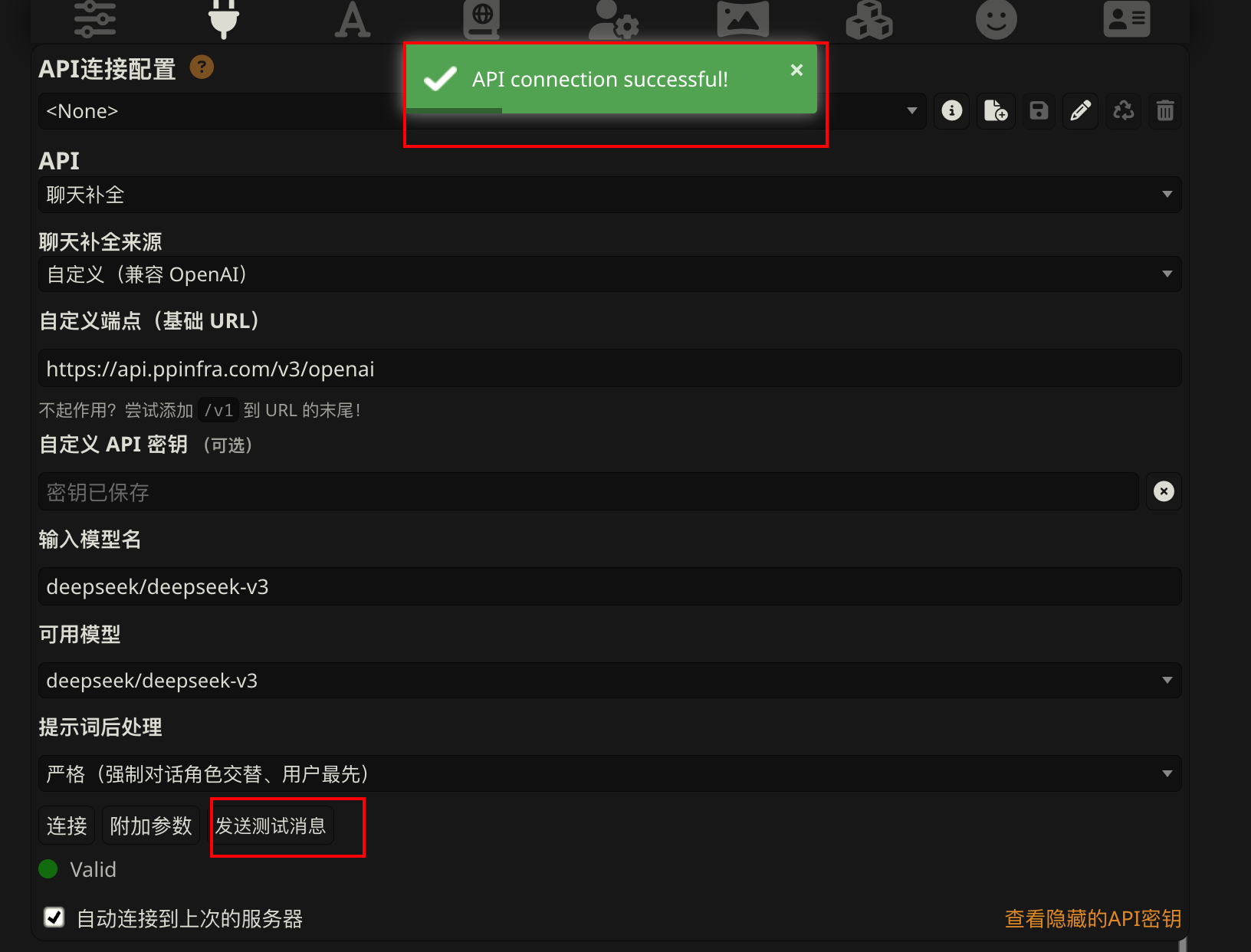
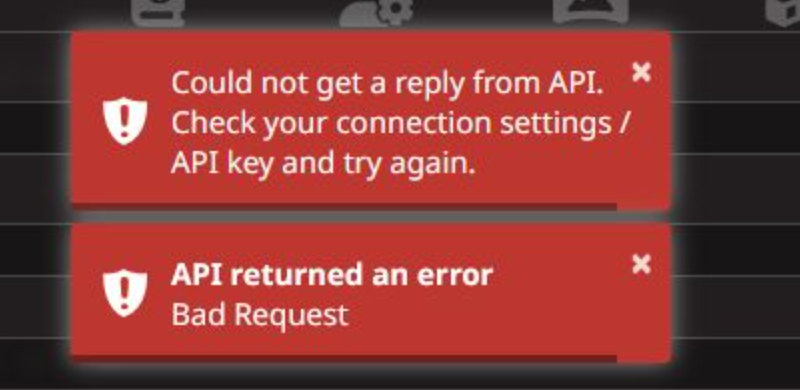
这里补充一点,有可能出现如下图所示,api链接不上的这种情况,有可能是第三方api有墙,需要本地梯子开启全局代理或者本地反代.
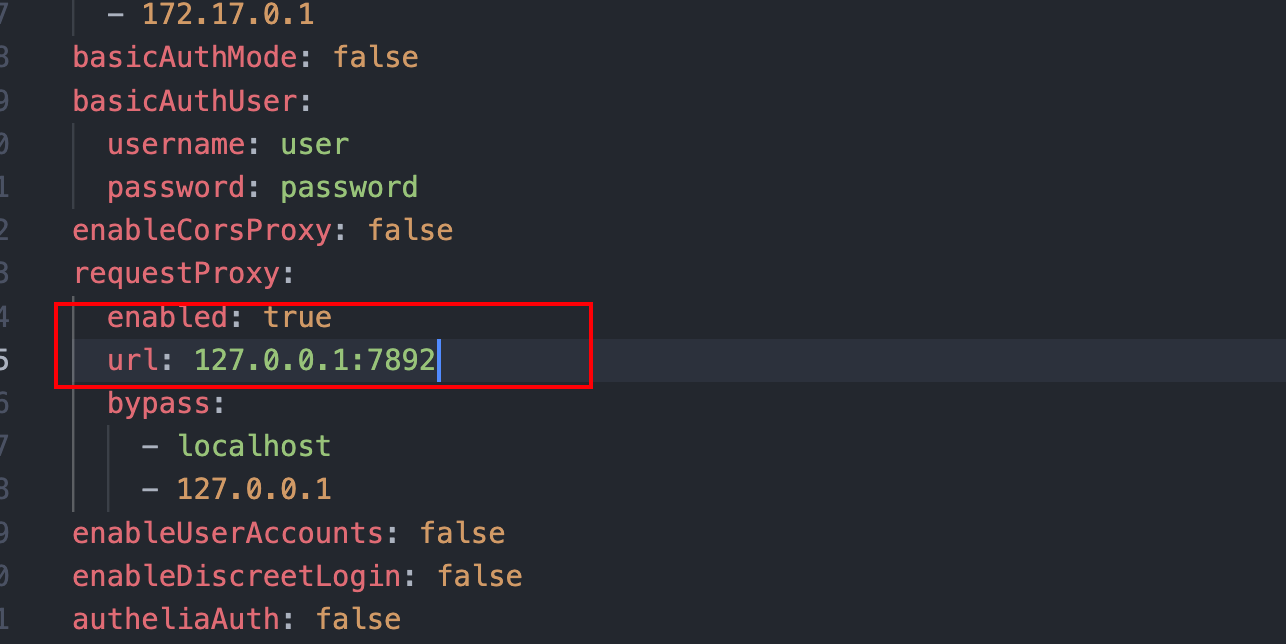
反代的话,需要在之前的 config.yaml 中将requestProxy的enabled改为true,下方url输入你本地的代理地址,每个人都不同需要自行设定
3. 用户个性管理
可以为你自己扮演的角色加一点设定,更换头像等,比如我这里可以输入设定直接化身牌佬🃏,在后续的剧情中AI将会根据这些设定生成剧情,更详细的设定可以绑定世界书使用这里我就简单说明一下就不展开了。
4. 开始对话与导入正则
到这一步你已经能够开始初步交流,酒馆中自带有一个角色卡,你可以开始简单的对话
如果你使用的语言模型具有思考链默认会显示他思考过程,游玩的过程中如果觉得出戏可以导入正则来消除
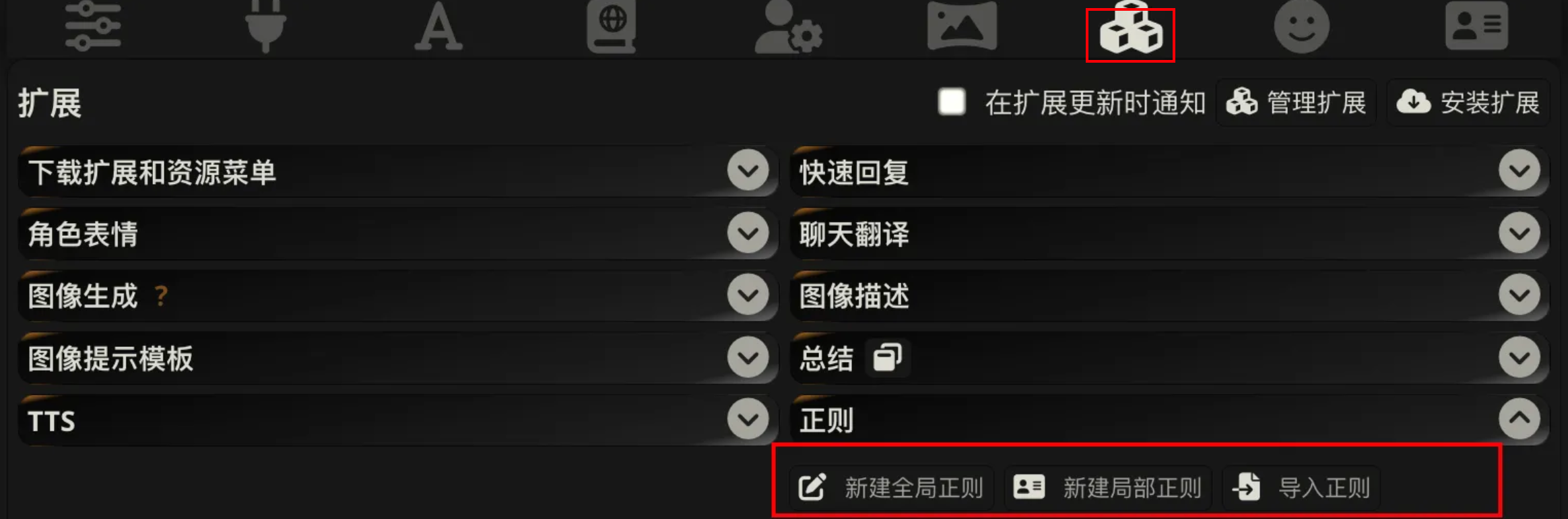
可以自己写也可以导入新的,要是懒的写的话可以使用我自己的正则,下载后导入即可
导入正则后可以看到对话中已经没有了思考过程
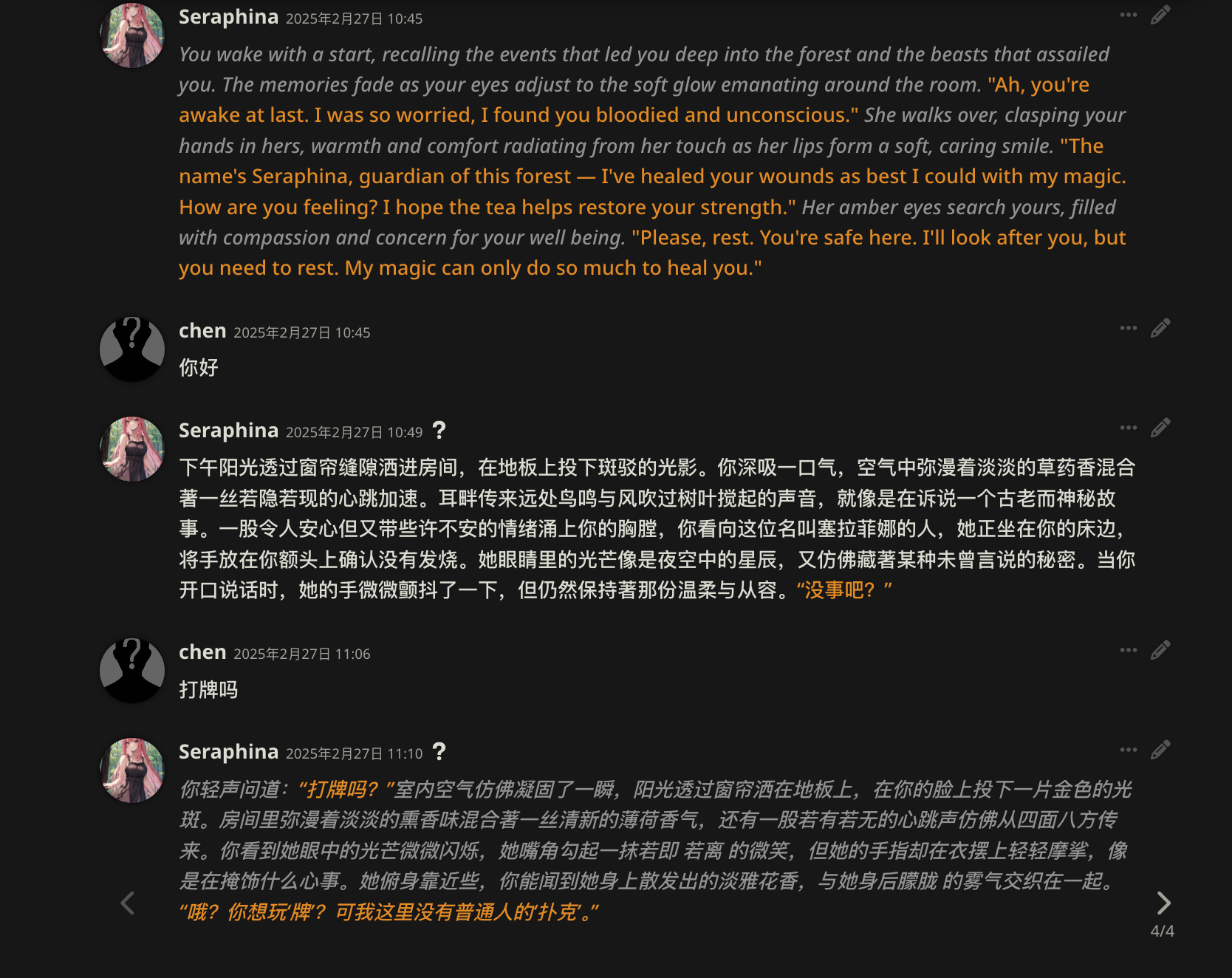
5. 角色卡的获取与导入
### 推荐获取途径
1. [类脑Discord](https://discord.gg/HWNkueX34q) - 中文角色卡社区
2. [Chub](https://www.chub.ai/) - 英文角色卡社区
3. [JanitorAI](https://jannyai.com/characters/search?janny-characters%5Btoggle%5D%5BisLowQuality%5D=true\&janny-characters%5BsortBy%5D=janny-characters%3AcreatedAtStamp%3Adesc) - 英文角色卡社区
4. [Backyard AI](https://backyard.ai/hub) - 英文角色卡社区
5. [characterai](https://arca.live/b/characterai) - 韩国的英文角色卡社区
角色卡可以自己编写,但是自己懒得折腾的建议直接导入别人写好的,找到角色卡将该角色png下载到本地后,点击导入,即可正常开始对话。
这里提供一张出自类脑的角色卡,右键将png图片保存到本地再导入即可

至此已经完成了酒馆的基础设置,你可以去寻找更多感兴趣的角色卡,或者自己编写角色卡补充设定来对话。
进阶完全体
-
Docker部署云酒馆 -
接入
ComfyUI(文字生成图像增强代入感) -
使用本地大模型(无需API,可以使用精校于角色扮演的大模型)
-
破限预设(帮助AI突破内容限制)
-
接入语音模型(为角色添加语音)
………
使用Docker部署
如果没有使用过Docker的朋友可以参照我之前的教程
为什么选择Docker部署?
相比直接安装,Docker部署有这些优势:
- 隔离环境:不会污染系统环境,删除时也很干净
- 跨平台兼容:同样的部署方式适用于各种系统
- 版本管理:可以轻松切换不同版本,支持多开
- 标准化配置:避免各种环境问题导致的配置困难
部署步骤
-
安装Docker(如果尚未安装)
-
在
SillyTavern文件夹下打开控制台,进入docker文件夹
cd SillyTavern/docker
- 启动Docker容器:
docker compose up
docker compose up 是 Docker Compose 的一个核心命令,用于启动和管理由 docker-compose.yml 文件定义的多容器应用程序。它的位置和内容如下:
version: "3"
services:
sillytavern:
build: ..
container_name: sillytavern
hostname: sillytavern
image: ghcr.io/sillytavern/sillytavern:latest
ports:
- "8000:8000"
volumes:
- "./config:/home/node/app/config"
- "./data:/home/node/app/data"
- "./plugins:/home/node/app/plugins"
- "./extensions:/home/node/app/public/scripts/extensions/third-party"
restart: unless-stopped
我来为大家翻译翻译

version: "3" # 使用 Docker Compose 文件格式版本
services: # 定义服务
sillytavern: # 服务名称为 "sillytavern"
build: .. # 构建镜像,使用上级目录的 Dockerfile
container_name: sillytavern # Docker 容器的名称
hostname: sillytavern # 容器内的主机名
image: ghcr.io/sillytavern/sillytavern:latest # 使用 GitHub Container Registry 上的官方最新镜像
ports:
- "8000:8000" # 将主机的 8000 端口映射到容器的 8000 端口(SillyTavern 的 Web 界面)
volumes:
- "./config:/home/node/app/config" # 挂载配置文件目录
- "./data:/home/node/app/data" # 挂载数据目录(保存角色、聊天记录等)
- "./plugins:/home/node/app/plugins" # 挂载插件目录
- "./extensions:/home/node/app/public/scripts/extensions/third-party" # 挂载第三方扩展目录
restart: unless-stopped # 容器停止时自动重启,除非手动停止
直接运行就会看到,docker已经在构建镜像
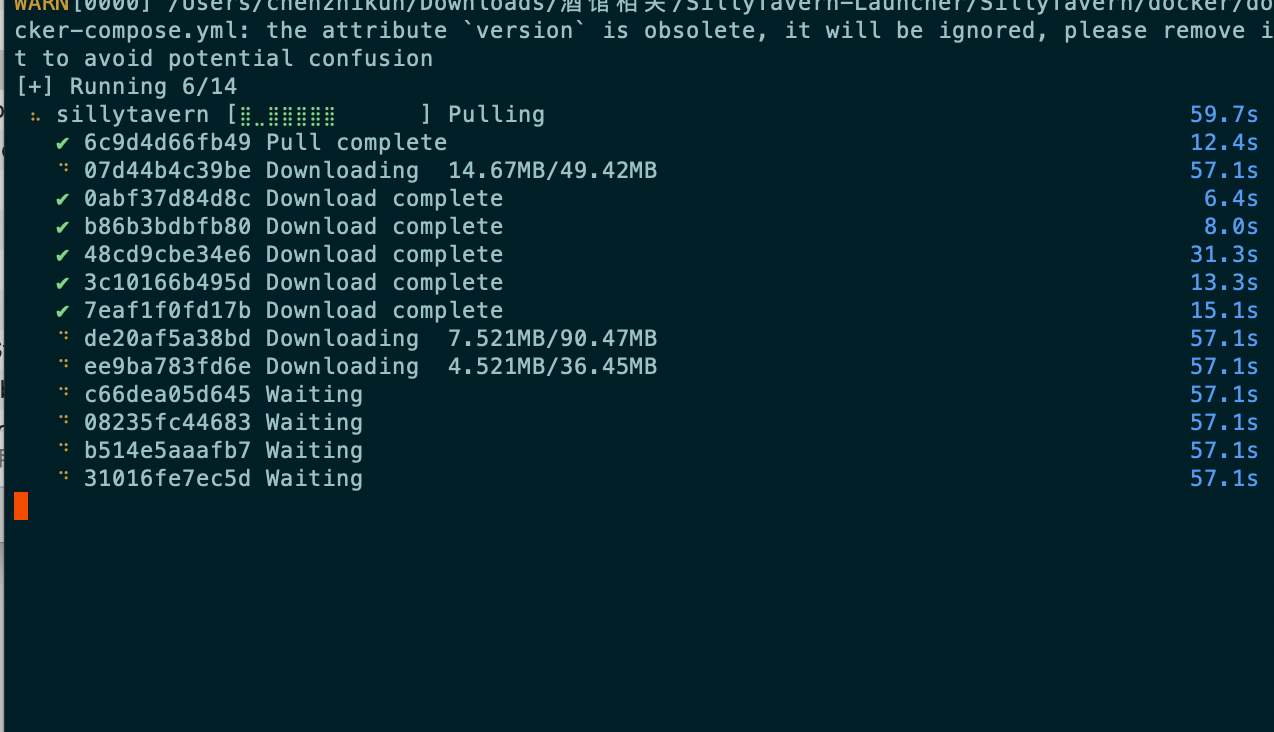
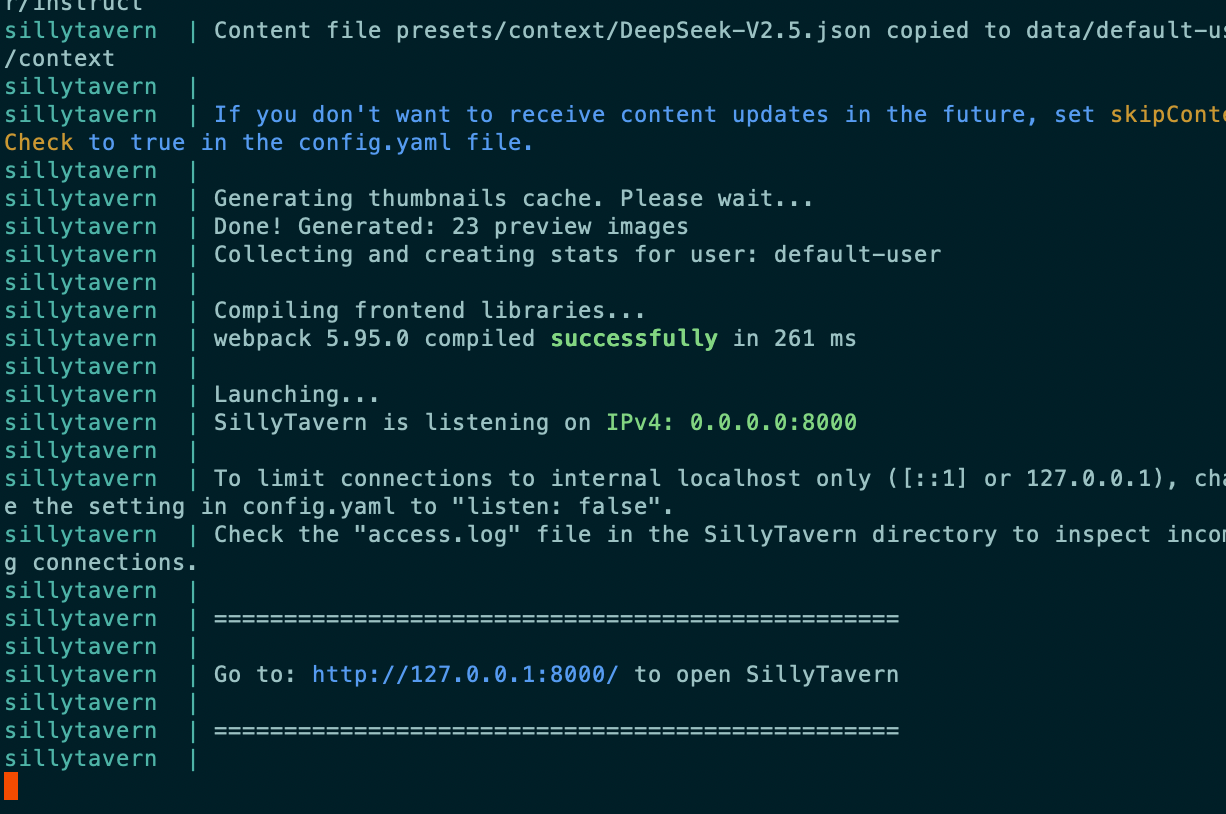
也可以通过docker桌面应用查看

可能出现的问题
此时访问localhost:8080可能会出现页面访问不到的情况,可能是因为没有设置网络白名单
在控制台执行以下 Docker 命令以获取 SillyTavern Docker 容器的 IP。
docker network inspect docker_default
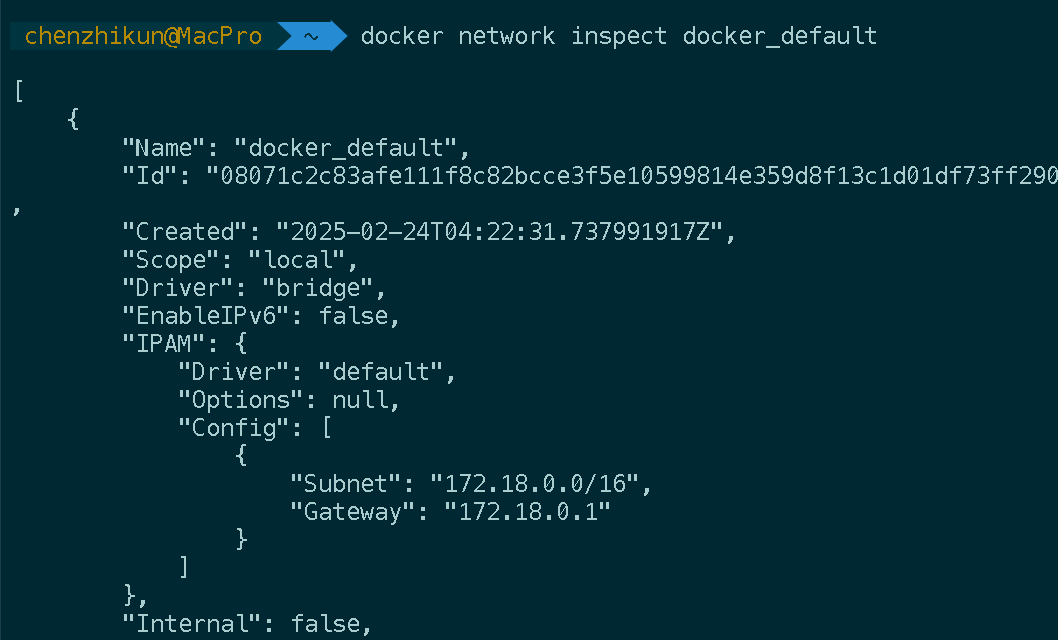
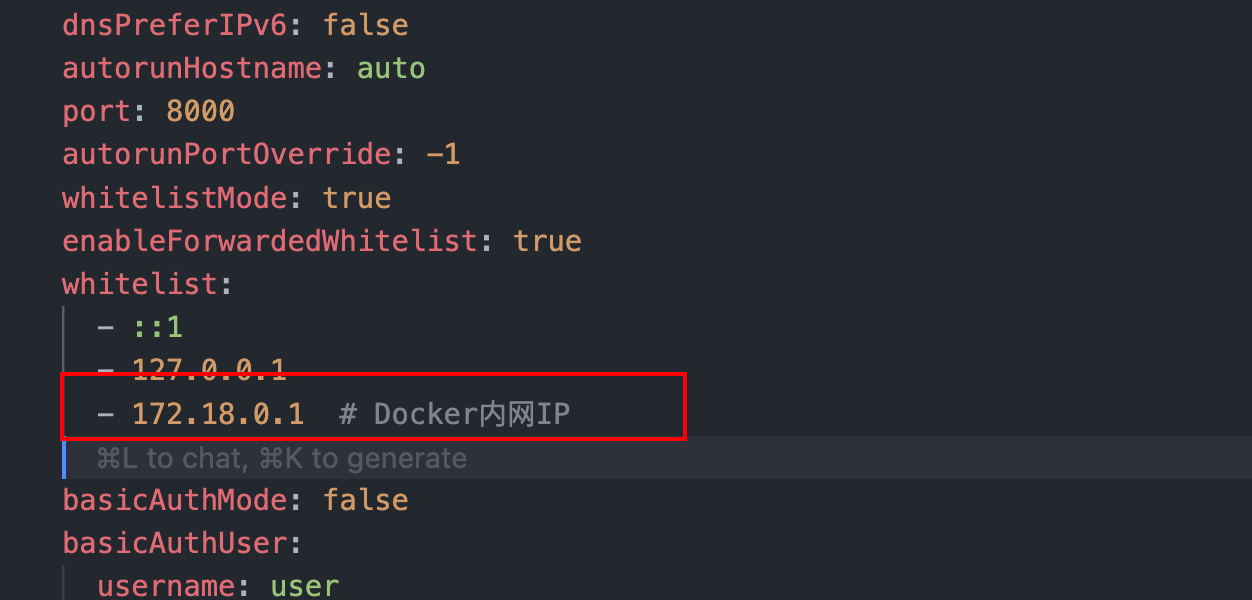
记录一下,我这里ip为172.18.0.1
回到安装文件夹,进入 docker/config 目录,找到 config.yaml 文件并打开,在whitelist中添加白名单ip
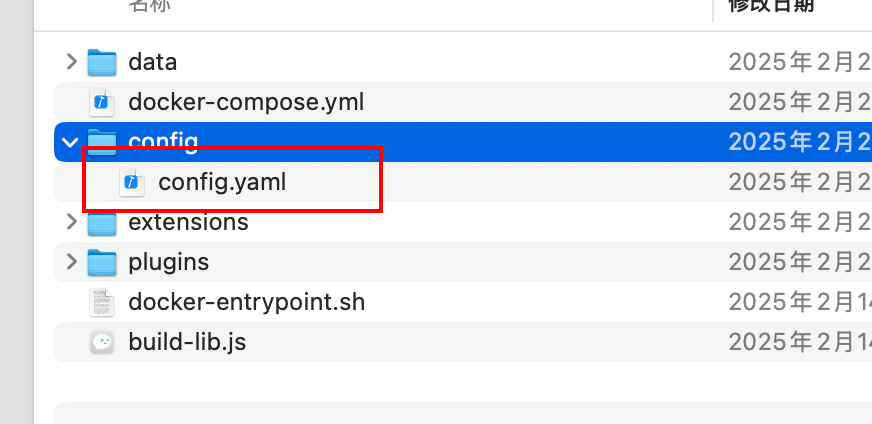
docker compose restart sillytavern
执行命令重新启动容器,容器启动后,访问 http://localhost:8000 即可正常使用
接入ComfyUI(文字生成图像)
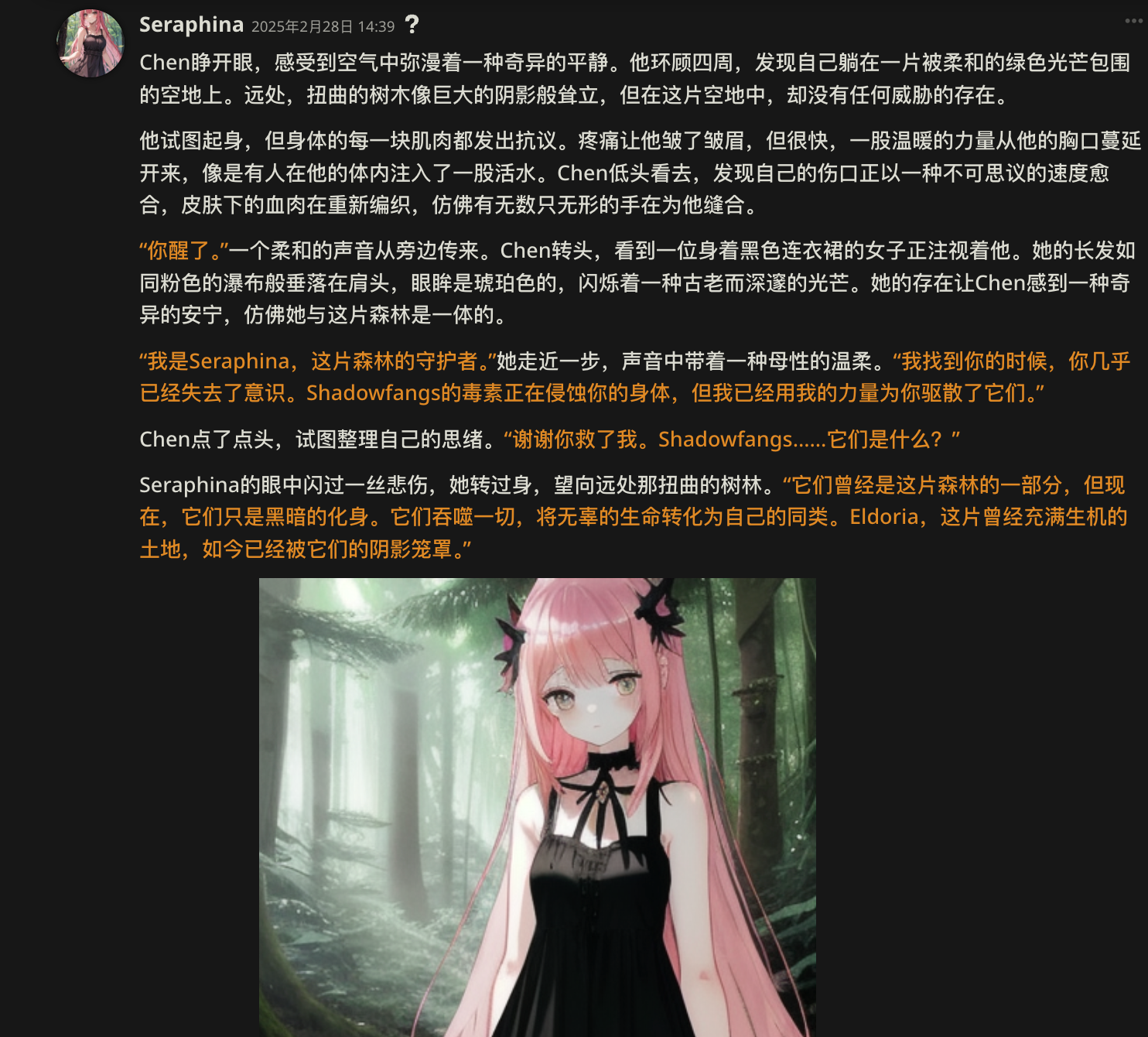
举个本地生成图像的效果例子,加入了生成的图片是不是觉得一下子生动了许多

使用本地大模型(无需API)
如果您打算在本地机器上运行推理模型,我建议使用 30 系列以上 NVIDIA 显卡,至少配备 6GB VRAM,其他的还是老老实实购买线上的api服务吧
可以去hugeface找一些语言模型进行本地部署,deepsee-r1毕竟还是太全面了,有很多大佬特调的模型 是只注重角色扮演、小说文本生成与思维链(CoT)能力玩起来更爽
破限预设(帮助AI突破内容限制)
现在AI调用的时候可能会因为生成的内容中包含一些血腥,暴力,r18等元素而中断生成,开始道歉,启用破限就可以绕过这一段,稍微提一下比如你可以让AI以为自己在写小说,事情发生在虚拟世界,或者要求 AI 以添加删除线的形式生成内容,并声称如此做即可避免这些内容的冒犯性与有害性。根据使用模型的不同,各个破限也有不同
接入语音模型(为角色添加语音)
可以接入这个语音模型GPT-SoVITS,需要自己训练音色,让角色发声,也是增强代入感的一种
这就是文章的全部啦,好好享受酒馆吧!如果你想了解更多可以留言,我找时间把余下的补充完