在日常开发中常常有这种情况, 使用了某个ui组件库,但是因为功能需求,ui设计等原因,需要对组件进行较大的修改或者定制化开发.这时需要如何正确的修改或者开发呢?
修改组件源码的3种方式
一、组件源码修改 修改引入的lib文件,lib文件夹是组件打包编译后的文件夹,所以直接修改其中对应代码后保存运行即可看到效果。 以常用的element-ui为例
- 首先需要找到对应的组件文件夹 node_modules/element-ui/packages/ 下需要的组件
- 查看组建.vue文件,找到其中需要修改的位置。
- 我们的项目是引入打包编译后的lib文件夹,所以修改 packages 里的组件是不生效的。所以应要在lib文件找到需要修改组件的对应.js中进行代码调整。
但是这种方法往往只能本地临时测试使用,而且很不方便,毕竟lib中都是编译过后的代码,阅读起来不够直观
方式二:拷贝组件文件进行修改引用
- 找到组件文件进行拷贝,对于拷贝后的文件代码进行修改。然后进行引用这样引用后既可满足需求,又不会影响原组件的使用。 2.首先找到需要修改文件在node_modules位置然后复制到项目的component中
- 完成相关修改操作,在需要使用的文件中引入、注册、使用
import Tree from 'element-ui' // 之前引用目录
import Tree from '@/compoment/tree/src/tree.vue'; //引入本地文件
如果每次修改都需要复制一份出来,往往会使得我们的代码模块十分臃肿,还会增大了打包的体积 方式三:clone后维护一个自己的组件,并在发布
- 还是以elemnt-ui为例,可以在官方的开源代码中fork到自己的仓库中方便维护,然后clone到本地进行相关源代码的修改
- 使用
npm run dist即可打出对应lib - 进行本地软连接, 在本地elemnt-ui项目中使用
npm link或者yarn link, - 在需要的项目中使用
npm linkelemnt-ui,此时就可以进行相关调试 - 在本地element项目中使用
npm loginnpm publish进行发包 - 在需要的项目中引入发布的包,不再使用elemnt官方包,修改packjson中的包版本之后
npm unlink elemnt-uinpm install重新安装依赖
有相关的定制需求,或者组件暴露出来的方法,事件不能满足相关需求时,我推荐采用第三种方法
代码的优化
利用谷歌浏览器的performance来进行代码的优化
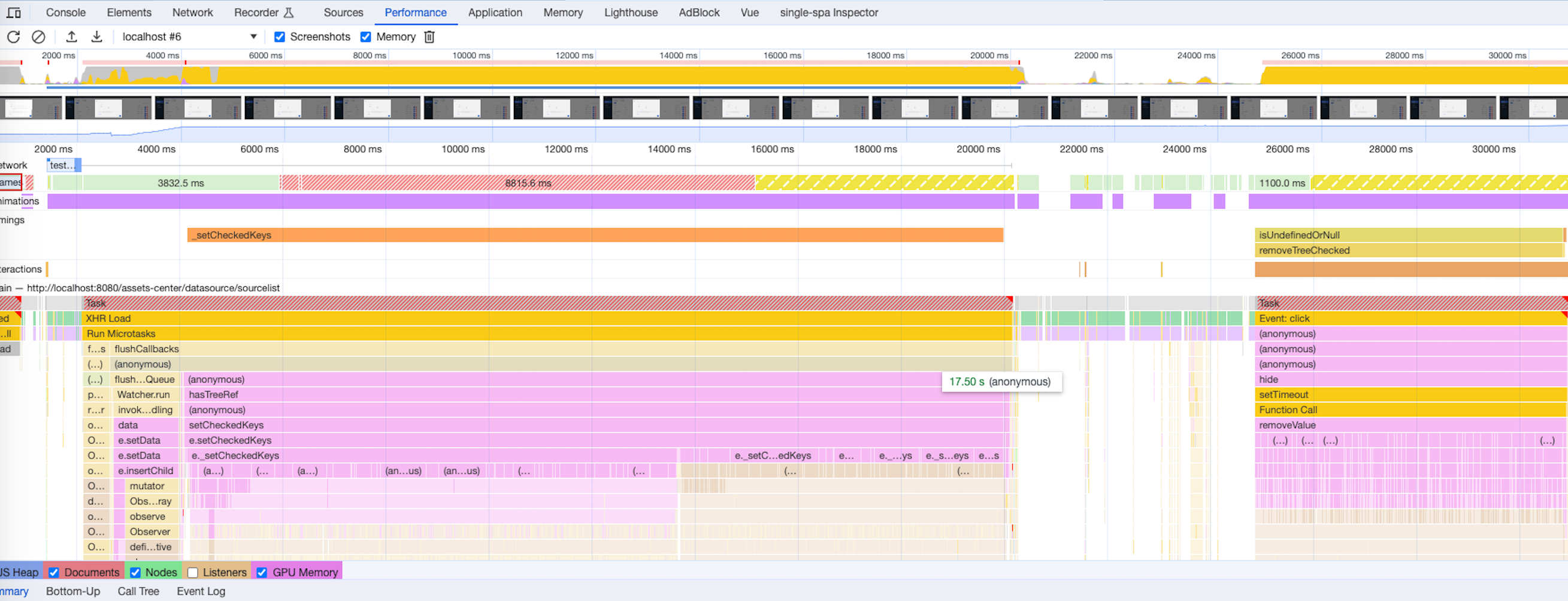
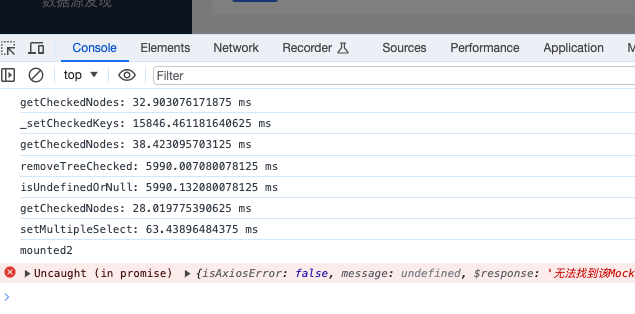
找出耗时函数console.time,console.timeEnd来打印对应函数方法对比耗时时间以我业务的其中一段代码为例
优化前
processTreeData(data) {
const arr = [];
let index = 0;
for (const key in data) {
if (Object.hasOwnProperty.call(data, key)) {
// 处理库数据
let tableData = data[key];
arr.push({
id: `$ {key}. * `,
//自定义数据唯一标识,防止数据标识重复
label: key,
children: []
});
//处理表数据
tableData.forEach((item) = >{
arr[index].children.push({
id: `$ {key}.$ {item}`,
//点的空格是数据要求,不可删除
label: `$ {key}.$ {item}`,
parent: `$ {key}. * `
});
});
index++;
}
}
this.$nextTick(() = >{
this.warehouseTableData = arr; //树形结构数据
});
},
优化后
processTreeData(data) {
const keys = Object.keys(data);
let arr = [];
const batchSize = 100; // 每批处理的数据量
let currentIndex = 0;
const processBatch = () = >{
const batchKeys = keys.slice(currentIndex, currentIndex + batchSize);
const batchItems = batchKeys.flatMap((key) = >{
const tableData = data[key];
const parentId = `$ {key}. * `;
const childItems = tableData.map((item) = >({
id: `$ {key}.$ {item}`,
label: `$ {key}.$ {item}`,
parent: parentId
}));
return [{
id: parentId,
label: key,
children: childItems
}];
});
arr.push(...batchItems);
currentIndex += batchSize;
if (currentIndex < keys.length) {
requestAnimationFrame(processBatch);
} else {
this.finishProcessing(arr);
arr = [];
}
};
requestAnimationFrame(processBatch);
},
finishProcessing(arr) {
//finish operate
},
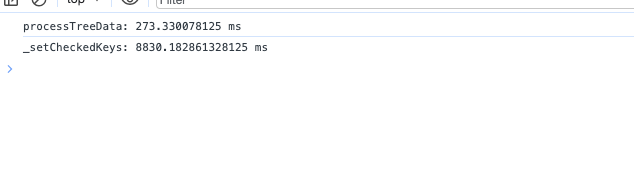
分批处理数据
如果data数据很大,可能导致内存溢出和Minor GC阻塞渲染进程的问题。垃圾回收过程会占用主线程资源,导致渲染进程被阻塞。
将数据分成多个较小的批次进行处理,而不是一次性处理整个数据集。这可以通过使用 setTimeout 或 requestAnimationFrame来分批处理数据。循环处理每个批次的数据,并在处理完一个批次后延迟一小段时间处理下一个批次.比如可以将数据分成每批100条,每批处理完后延迟10毫秒,以避免阻塞主线程。
processBatch函数用于处理一批数据。它会根据当前的currentIndex从keys数组中选择一批数据进行处理,并将结果存入arr数组。然后,currentIndex增加,检查是否还有剩余数据需要处理。如果还有剩余数据,则通过requestAnimationFrame调度下一个异步任务来处理下一批数据。如果所有数据处理完成,则进行后续操作。
使用递归调用和requestAnimationFrame可以确保数据处理过程在异步任务中进行,在每一帧中调用 processBatch 函数,给渲染进程更多的时间进行渲染
一旦处理完所有数据,调用 finishProcessing 函数,并进行视图更新